

Парсинг сайта с JavaScript на Python
План статьи:
- Введение
- Почему пользователь видит всё корректно?
- Как устроены страницы с динамическим контентом.
- Библиотека Selenium. Эмуляция обычного браузера.
- Практика. Парсим новостной сайт.
Многие начинающие программисты на Python часто сталкиваются с проблемой: при парсинге сайта программа не находит элемент на сайте, хотя при его обычном посещении через браузер он присутствует. Оно и понятно, ведь вы, скорее всего, получаете HTML-документ через GET-запрос на сайт с помощью стандартной библиотеки requests.
- Почему пользователь видит всё корректно?
Но почему в браузере Вы видите весь контент, в отличии от Вашей программы? Дело в том, что при переходе на нужный домен браузер получает HTML-документ, CSS-стили и JavaScript. С первыми двумя, я думаю, всё понятно - они нужны для базовой отрисовки страницы. А вот JavaScript отличается от остальных. Это язык программирования, поддержка которого присутствует во всех браузерах. Чаще всего его применяют для добавления анимаций и расширения функций сайта с помощью изменения DOM-дерева.

- Как устроены страницы с динамическим контентом.
Сейчас набирает популярность создание своих SPA-приложений. Это так называемые одностраничные приложения (Single Page Application). Весь сайт отображается с помощью JavaScript, а в HTML-документе прописана лишь загрузка нужного JS-файла. Отключив JavaScript в своём браузере Вы, чаще всего, увидите пустую страницу с подобным текстом: “Для отображения сайта необходим JavaScript”..
Не сложно догадаться, что парсинг такого сайта через Python и библиотеку requests не получится. Перейдём к коду и практическим примерам.
- Библиотека Selenium. Эмуляция обычного браузера.
Для Python была разработана библиотека Selenium. Предназначена она для автоматизации действий в веб-браузере, выполнения рутинных задач и тестирования Web-приложений.
Давайте установим её:
pip3 install selenium
Для того, чтобы работать с библиотекой, нам также понадобится WebDriver. WebDriver нужен для эмуляции обычного браузера, который будет управляться через Selenium. Советую не заморачиваться и установить веб-драйвер для того браузера, который установлен у вас на ПК. В моём случае я использую ChromeDriver.
Создаём Python-файл для будущего парсера. В директорию с ним переносим ранее установленный веб-драйвер.
- Практика. Парсим новостной сайт.
В качестве объекта для практики я выбрал новостной сайт Meduza. На сайте много информации, из-за чего процесс парсинга станет интересней. При парсинге через requests информация о новостях не отображается, ну и не должна):
Весь код будет написан в функциональном стиле. Для начала импортируем нужную библиотеку и инициализируем сам WebDriver:
from selenium.webdriver import Chrome
if __name__ == “__main__”:
driver = Chrome(executable_path="./chromedriver.exe")
Чтобы не добавлять ChromeDriver в переменные среды моей ОС я передал путь к драйверу в аргументе executable_path.
При запуске данного кода не произойдёт ничего необычного: у вас запустится окно браузера с базовым адресом “data:,”.
Для перехода по страницам в Selenium используется метод get у класса драйвера. Принимает всего лишь 1 аргумент - url. Поэтому напишем следующее:
driver.get(“https://meduza.io/”)
Сразу определимся с тем, что нам нужно. Мы будем парсить картинку, заголовок и дату публикации. Исходя из этого в нашей программе будет 4 функции для парсинга (get_news, get_image, get_title, get_date) и 1 для вывода.
Для карточки новости соответствует класс “RichBlock-root”:
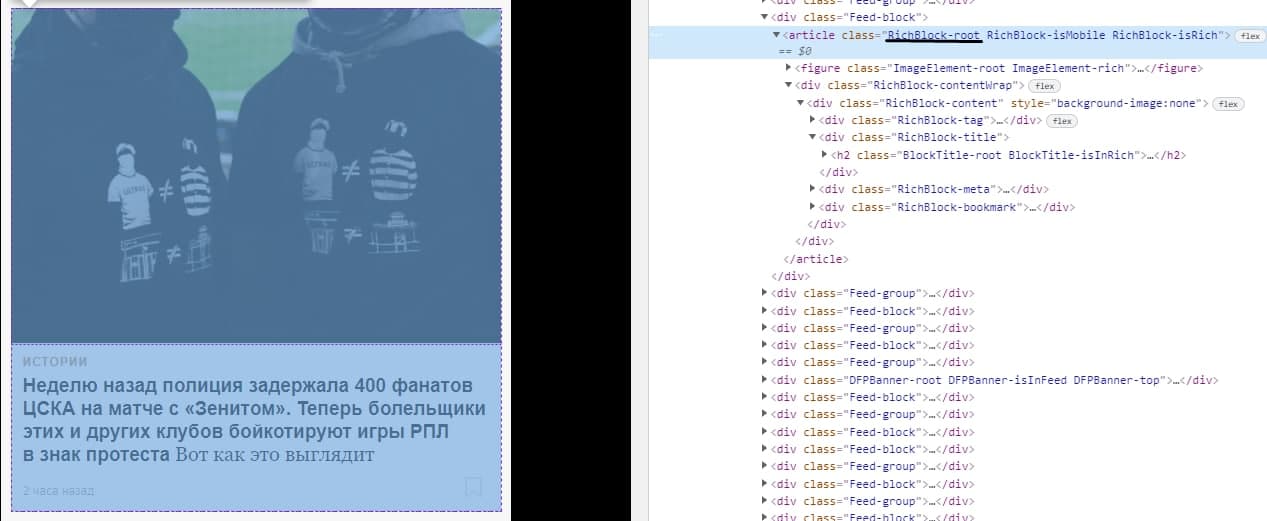
Чтобы производить поиск по чему-либо необходимо импортировать класс By:
from selenium.webdriver.common.by import By
Напишем саму функцию:
def get_news():
news = [] news_elements = driver.find_elements(By.CLASS_NAME, "RichBlock-root")
for element in news_elements: data = {
"image": get_image(element),
"title": get_title(element), "date": get_date(element),
}
news.append(data)
return news
Инициализируем пустой список и находим все элементы карточек новостей. Для каждой карточки мы получаем изображение, заголовок, дату и записываем это в переменную data. После всего этого мы добавляем данные в список, который мы возвращаем в конце функции.
Сейчас в значения для данных функции записываются несуществующие функции. Давайте исправим это. Создавать функции будем по порядку.
Чтобы получить картинку нам нужно выбрать класс “ImageElement-root”, а затем первый элемент с тегом “source”:
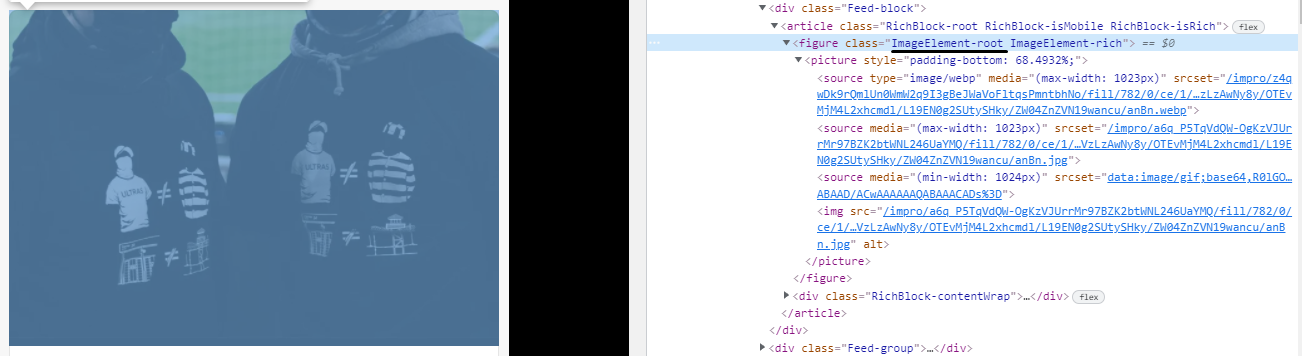
Но как мы видим, у “source” нет никакого текста, только атрибут srcset. Для получения атрибутов мы используем метод get_attribute на элементе.
def get_image(element):
images_element = element.find_element(By.CLASS_NAME, "ImageElement-root")
image_element = images_element.find_element(By.TAG_NAME, "source")
return "https://meduza.io" + image_element.get_attribute("srcset").strip()
Возвращаем абсолютную ссылку на картинку. При получении атрибута srcset в начале образовался отступ. Чтобы его убрать используем функцию strip.
Заголовок карточки помещён в тег a с классом “Link-root”.

Пишем функцию:
def get_title(element):
title_element = element.find_element(By.CLASS_NAME, "Link-root")
return title_element.text
Весь текст, который находится в этом элементе, получаем с помощью переменной text.
И, наконец, дата создания. В этом случае ищем элемент по классу “Timestamp-module_root__coOvT”

Создаём ещё одну функцию:
def get_date(element):
date_element = element.find_element(By.CLASS_NAME, "Timestamp-module_root__coOvT")
return date_element.text
Тут, я думаю, объяснять ничего не нужно.
Последняя функция в нашем коде - print_data_news:
def print_data_news():
news_items = get_news()
for news in news_items: print(f"""Изображение: {news['image']}Заголовок: {news['title']}Дата создание: {news['date']}""")
Осталось добавить в точку входа (после создания драйвера и перехода на страницу) вызов функции print_data_news().
Наконец-то мы написали наш парсер динамической страницы. После запуска программа выдаёт следующее:

Это можно считать успехом, ведь все наши цели выполнены и мы можем спокойно отдохнуть