Ни OWASP’ом единым. Пять веб-уязвимостей, про которые все забывают
Вы помните как выглядели сайты в самом начале становления интернета? Парочка html страниц с минимальным функционалом в виде просмотра статичной информации.
Всего за пару десятков лет веб сайты превратились в очень мощные приложения, способные удовлетворить потребности чуть ли не любого пользователя. Не хватит и нескольких циклов статей, чтобы описать количество технологий на сайтах.
Как читатели блога по информационной безопасности вы наверняка знакомы с такими уязвимостями как SQL Inj, XSS, SSRF и т.д.
Но список веб уязвимостей не держится исключительно на OWASP Top 10.
В этой статье я расскажу про пять интересных веб уязвимостей в различных технологиях, про которые все почему-то незаслуженно забывают.
Цель этой статьи дать основы тех или иных векторов атак и показать, что мир уязвимостей не ограничен списком OWASP Top 10.
- CORS
Стоит начать с того, что одной из самых распространенных клиентских уязвимостей является XSS, но XSS не имеет особого смысла, если каким-то образом разграничен доступ к доменам. Т.е если существует политика одного источника SOP. Но SOP неудобен, потому что зачастую нам нужно получать данные с родственных доменов. CORS позволяет разделить доступ доменов друг к другу
Работа CORS происходит при помощи заголовков Origin, которые обозначают домены с которыми может идти обоюдное сообщение:
В заголовке запроса:
Origin: domen.com
В заголовке ответа:
Access-Control-Allow-Origin: domen.com
Если отсутствует фильтрация заголовка и CORS настроен неправильно, то уже на самом первом и самом простом этапе можно провести зеркальную проверку, просто вписав в заголовок запроса любой домен, если он отразится в Access-Control-Allow-Origin, значит есть серьезная уязвимость, позволяющая создавать вредоносные запросы от имени другого пользователя. Т.е мы можем создать страницу, которая будет от имени пользователя обращаться к целевому ресурсу(например, запрашивать какой-то ключ и забирать его из ответа), и это сработает, т.к при проставлении заголовка Origin мы можем работать с любого выбранного ресурса.
Если же произвольный домен не зеркален в ответе, то такая атака не получится, т.к запросы к доменам ограничены рамками легитимных доменов, и провести запросы с сайта злоумышленника просто не получится.
Но может быть ситуация и похуже, когда у нас отдается следующий ответ при заголовке Origin:
Access-Control-Allow-Origin: *
Эта строка означает, что запрос разрешен с любого ресурса
Так же стоит упомянуть про заголовок ответа на совместное использование конфиденциальных данных
Access-Control-Allow-Credentials: true
Думаю, не нужно объяснять, какую опасность несет неправильно настроенная политика CORS, позволяющая создавать конфиденциальные запросы на получение критической информации от чужого имени
- CRLF
Наверняка вы слышали об этой уязвимости возврата каретки и переноса строки.
Вообще, давайте поймем, что такое CR и LF
CR - это возврат каретки \r (или в формате URL %0d). Возврат каретки происходит, когда вы нажимаете Enter, т.к одновременно происходит
LF - перенос строки \n (или в формате URL %0a)
Если вы хоть мало мальски знакомы с программированием, то эти символы не покажутся вам чем-то диким и незнакомым. CRLF не применяются исключительно в программировании, так же они используются для разделения частей в HTML и запросов/ответов веб сервера. Т.е эти символы играют очень важную роль в работе веб приложений.
Давайте сразу уточним, что CRLF Inj не совсем самостоятельная атака, она помогает проэксплуатировать другие не менее известные уязвимости:
1) XSS
2) Произвольная запись в логи
3) HTTP requests splitting
Например, на сайте есть функционал ввода имени пользователя, которое будет отдаваться ответом в заголовке Set-cookie:
HTTP/1.1 200 OK
...
Set-Cookie: name=John
Но что если мы введем John\r\n{Любые произвольные заголовки}\r\n\r\n{Вредоносная http страница}
Вариант выше разделил http ответ символами CRLF и дал возможность писать как произвольные заголовки в ответе(как мы помним заголовки сами по себе разделяются этими символами. Более того вы можете включить наглядную демонстрацию символов в том же BurpSuite), так и вредоносный html контент, который может вызвать xss.
Т.е ответ будет иметь примерно такой вид:
HTTP/1.1 200 OK
...
Set-Cookie: name=John
Произвольный: заголовок
Вредоносная http страница
Если проставить CRLF вручную, то:
HTTP/1.1 200 OK
...
Set-Cookie: name=John\r\n
Произвольный: заголовок\r\n
\r\n
Вредоносная http страница
- HTTP Request Smuggling
Относительно свежая атака, которую не так просто понять. Материалов по ней немного особенно в русскоязычном сегменте.
В чем суть атаки?
Современные веб-приложения могут поддерживать одну интересную схему работы в виде кэш сервер -> бэкэнд сервер.
Кэш сервер могут также называть обратный прокси или фронтенд сервер.
Такая схема достаточно удобна, когда у нас имеется очень большой ресурс, на который можно подгружать статику(картинки и видео) через фронтенд сервер и распределять нагрузку по бэкэнд серверам, попутно вынимая кэшированные страницы из обратного прокси для ускорения работы.
Но у такой схемы есть один интересный недостаток, который и приводит к атаке HRS(HTTP Request Smuggling)
Заключается он в заголовках
Если вы хоть раз анализировали HTTP траффик, то наверняка вы видели два заголовка:
1) Transfer-Encoding
2) Content-Length
Суть в том, что фронтенд и бэкенд сервер могут воспринимать эти заголовки по разному, вследствие чего может возникнуть пресловутая контрабанда запроса, которая может привести к обходу WAF, XSS и даже захвату сессии пользователя.
Вообще HTTP 1.1 поддерживает одну интересную функцию, позволяющую передавать запросы «конвейером», суть в том, что открывается постоянное TCP соединение, по которому запросы следуют друг за другом. Возможно это благодаря заголовку Connection: keep-alive. Т.е два разных пользователя могут передавать запросы в одном потоке. Но как же сервер поймет, где запрос закончен и где идет следующий запрос?
Именно благодаря заголовкам длины сервер отличает запросы друг от друга
Пример работы Content-Length:
GET / HTTP/1.1
Host: google.com
Content-Length: 5(длина сообщения)
hello(5 символов)
Пример работы Transfer-Encoding
GET / HTTP/1.1
Host: google.com
Transfer-Encoding: chunked(порционный запрос)
5(длина порции сообщения)
hello(5 символов)
0(окончание порции первого фрагмента запроса)
11(длина порции сообщения)
hello world(11 символов)
0(окончание порции второго фрагмента запроса)
Обратите внимание, что конец фрагмента(Transfer-Encoding работает именно при помощи фрагментирования) оканчивается нулем
Но что если фронтенд сервер понимает только CL(Content-Length), а бэкэнд только TE(Transfer-Encoding)?
Верно, фронтенд сервер пропустит запрос с двумя такими заголовками и пустит вредоносный запрос на бэкэнд. Но стоит учитывать, что TE всегда имеет преимущество и поэтому нужно обфусцировать TE заголовок для того, чтобы кэш сервер пропустил его вперед и случилась контрабанда.
Примеры обфускации(обратите внимание на пробелы):
Transfer-Encoding : chunked
Transfer-Encoding: xchunked
Transfer-Encoding : chunked
Transfer-Encoding: chunked
Transfer-Encoding: x
Рассмотрим на практике(на примере CL-TE схемы)
Мы можем составить такой запрос:
POST /file.txt HTTP/1.1
Host: host.com
Transfer-Encoding : chunked(обфусцирован пробелом)
Content-Length: (тут длина ВСЕГО запроса) 0
GET /404page HTTP/1.1
Host: host.com
Такой запрос пустит полностью фронтенд сервер(т.к он игнорирует порционный запрос TE заголовка), но вот бэкэнд сервер разобьет его на ДВА запроса, а именно на POST запрос файла file.txt и на GET запрос страницы /404page. Он обработает запрос на файл, но запрос на страницу 404 он отдаст уже следующему пользователю в ответе, т.к он встанет в очередь и будет ждать того, кто придет следующим.
Думаю, очевидно, что легким баловством в виде редиректа на 404 страницу злоумышленники не обойдутся, ведь если есть передача параметром в те же комментарии, что им мешает составить запрос таким образом, чтобы куки другого пользователя с помощью HRS не вставились в его комментарий вследствие атаки?
Понятное дело, что уже придуманы инструменты для такой экзотичной уязвимости
Например дополнение smuggler в Burp Suite
Для начала его нужно скачать с вкладки Extender
Давайте захватим запрос и правой кнопкой мыши направим его в Smuggler

Зададим необходимые параметры для смаглинга:
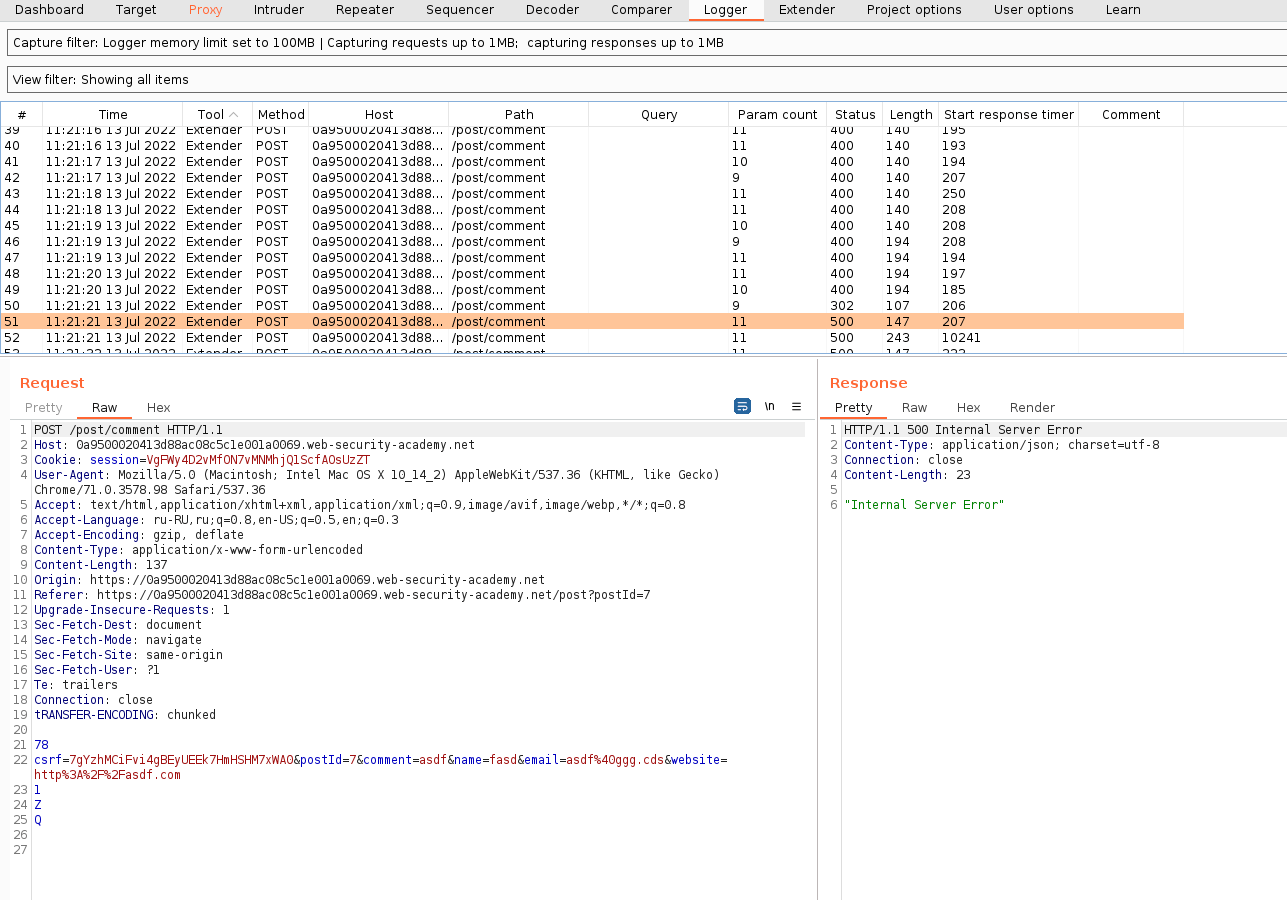
Теперь посмотрим на результаты и увидим, что смаглинг сработал и есть подозрительное поведение:

Перейдем в Logger и поищем интересные ответы. Мы нашли код ответа 500, который выдал сервер в связи с атакой HRS, а 500 код ответа уже может привести к DOS атаке.
- Web Sockets
Представьте, что вы разрабатываете мессенджер и вам нужно держать одно стабильное соединение для обмена сообщениями в рамках веб-интерфейса. Логично, что обычная схема HTTP формата запрос-ответ не подойдет, т.к будут высокие нагрузки на сервер, да и вообще люди придумали WebSockets.
Сокеты позволяют держать стабильную сессию для обмена сообщениями. При начале обмена сообщениями через сокеты нужно инициировать соединение.
Запрос на приветствие веб сокеты понимают при помощи заголовков Sec-WebSocket-Key и Sec-WebSocket-Accept
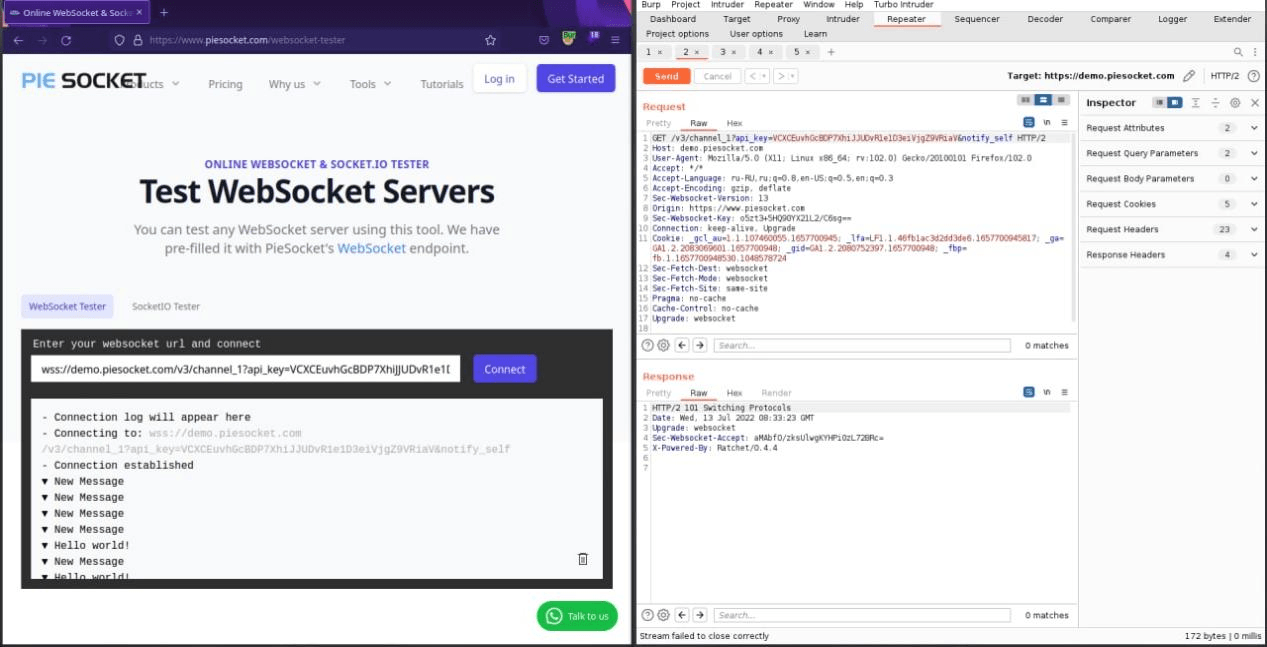
Далее идет смена протокола на сами веб сокеты с ответом 101
После чего мы уже можем обмениваться сообщениями в непрерывном формате
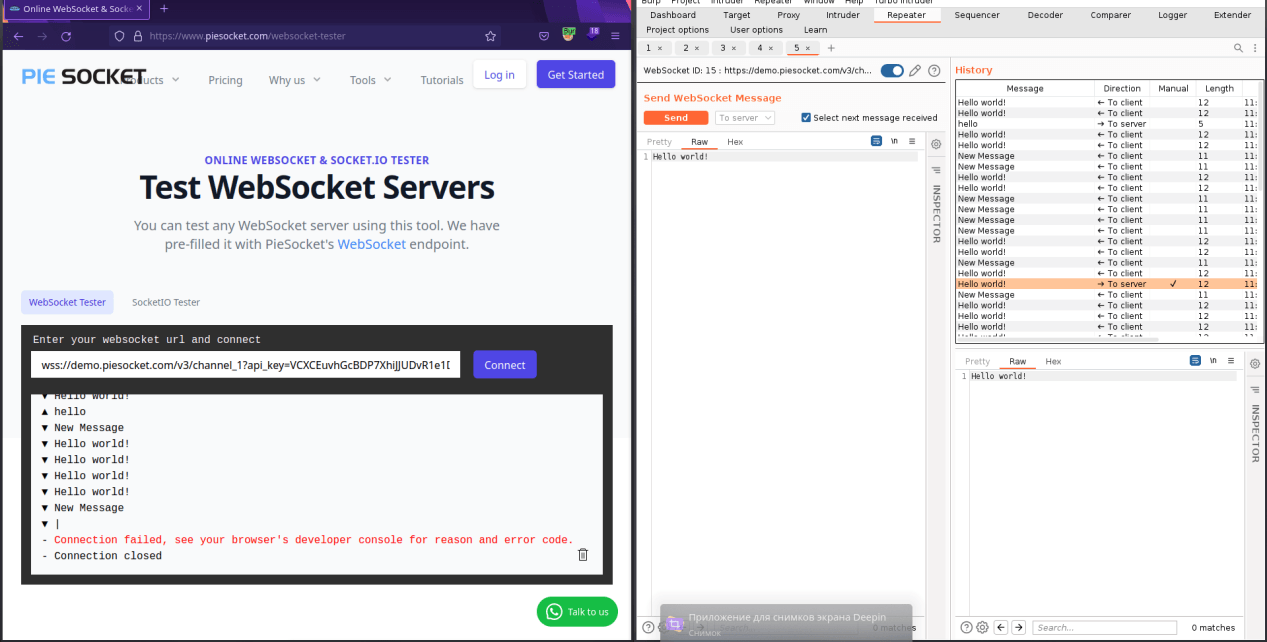
Какие же могут быть проблемы?
Существует атака CSWSH(Cross-Site WebSocket Hijacking)
Ее суть заключается в отсутствии фильтрации данных, посылаемых на сокет
Так же стоит упомянуть про модель Origin-based. Да-да, это именно тот ориджин, созвучный с политикой CORS. Суть в том, что веб сокеты не поддерживают SOP, поэтому все уязвимости подделки origin ресурса при инициации рукопожатия будут перетекать и сюда.
Т.е если мы создадим страницу на своем домене evil.com, содержащую код, инициирующий рукопожатие с веб сокетом, то юзер будет посылать вредоносные запросы от имени своей cookie-сессии. Естественно, это будет работать только в том случае, если нет проверки заголовка origin.
То бишь любой ресурс сможет совместно использовать функционал целевого веб-приложения с сокетами и посылать ему не легитимные запросы от имени другого человека, что может привести к CSRF, XSS и Hijacking’у как таковому.
Это становится особенно опасным, когда так же отсутствует фильтрация посылаемых с домена злоумышленника данных. Мало того, что можно посылать те же XSS пейлоады и получать рефлективные или хранимые XSS при прямом контакте злоумышленника и сервера, так еще и с неправильно настроенным origin злоумышленник имеет полный карт бланш на проведение атак без непосредственного участия, просто имея в распоряжении вредоносный домен, эксплуатирующий origin заголовок.
- SSTI
Давайте представим, что мы должны реализовать функционал приветствия пользователя при смене имени, фамилии и других личных параметров и вывести их в рамках текущей веб страницы. Логично в такой ситуации использовать так называемые шаблонизаторы, которые будут вставлять, как это ни странно, шаблонизированные данные для удобства вывода.
То есть шаблонизаторы генерируют страничку исходя из шаблонизированных данных
От сайта к сайту шаблонизаторы могут разниться, есть шаблонизаторы для php, python, ruby и т.д. Соответственно синтаксис у каждого шаблонизатора различен.
Давайте рассмотрим пример кода шаблонизатора twig языка php:
<?php
...
$hello_user = $twig->render("Hello {{name}}", array("name" => $_GET["name"]));
...
?>
Наверняка вы часто встречались с так называемым форматным выводом в программировании. Так вот, любой шаблонизатор работает примерно так же. То бишь по шаблону вставляются данные в форматный вывод. Но что если ввод не фильтруется?
Что мешает нам написать вместо имени строку {{}}? Верно, ничего, особенно, если учитывать что шаблонизатор это воспримет как форматную строку внутри форматной строки, где можно писать достаточно интересные вещи. Самым популярным способом обнаружения SSTI будут являться арифметические операции.
Запишем {{7*7}}. Если страничка отдаст «Hello 49», то у нас есть уязвимый шаблонизатор, т.к мы смогли вставить языковое выражение внутрь форматной строки
Как мы только что поняли, атака SSTI может выполнять языковые выражения. А что если мы выполним действие в рамках класса языка, который читает файлы или исполняет команды операционной системы? Правильно, мы получим RCE
Но все не так просто. Когда мы пишем SSTI пейлоад, мы находимся, так скажем, в рамках класса, работающего со строками, соответственно нам нужно «убежать» из этого класса и получить доступ к классу, работающему, например, с файлами
Обычно SSTI пейлоад выглядит примерно таким образом:
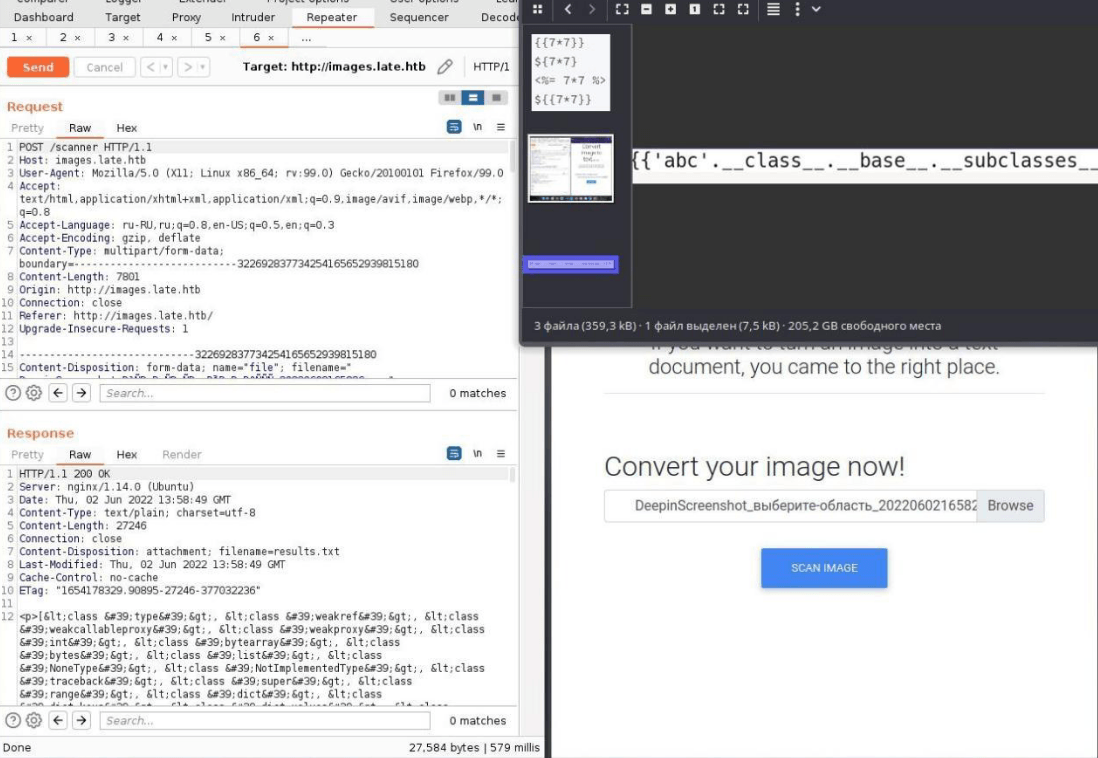
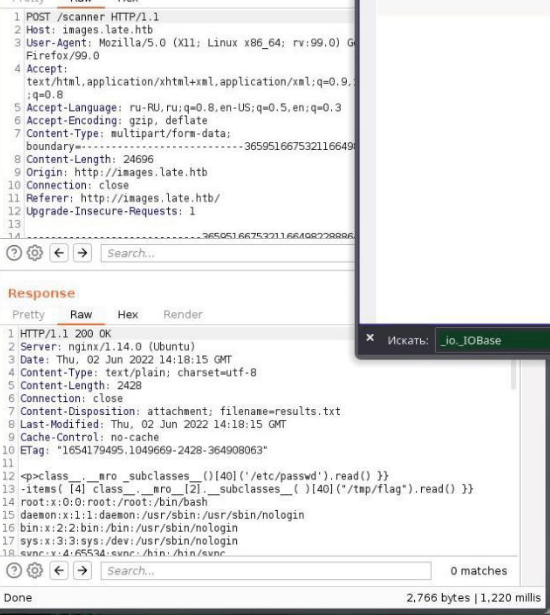
{{‘ ‘.__class__.__mro__[7].__subclasses__()[63](‘/ etc/passwd’).read() }}
Первым делом мы посылаем пустую строку, после чего через объект class и последующее обращение к mro(с помощью класса mro можно получить все унаследованные классы в виде массива). После чего мы ищем необходимого «родителя» для нашего целевого класса(это спокойно гуглится, но в нашем случае пусть родителям класса чтения файлов будет класс в массиве с индексом 7), после чего с помощью subclasses мы получаем соответственно сабклассы, где нас снова встретит массив данных, где мы точно так же можем обращаться по индексу. Именно здесь и будет находится наш класс, с помощью которого мы будем читать локальные файлы на сервере(в нашем случае это класс с индексом 63). После чего в аргументы мы передаем само имя файла и функцию прочтения файла.
Немного примеров из жизни:
В рамках CTF была SSTI уязвимость. Суть шаблона состояла в том, что генерировался текстовый файл, заключенный в теги <p></p>, в который записывался распознанный с загруженной картинки текст.
На скриншотах виден посылаемый пейлоад и отданный массив классов, через которые удалось добраться до функции чтения файлов