

Флаги и таски. Введение в CTF для самых маленьких
В самом начале, когда только зарождалось понятие "хакер" люди связывали это слово с преступлениями и чем-то противозаконным. Сейчас же за любую дыру в системе компании готовы платить огромные деньги. Поиск уязвимостей стал сложнее, а компаний все больше. В пример можно привести площадку HackerOne. Но прежде чем на ней работать, потребуются определенные знания и тренировки. Где их искать? Все очень просто. Требуется всего лишь прохождение CTF. Что это такое и как с этим работать я расскажу в этой статье.
План работы
Перед этим давай я посвящу вас в наши планы. Расписывать много не стану. Весь план статьи вы можете увидеть ниже.
- Что такое CTF?
- Термин CTF и его описание
- Алгоритмы работы
- OSINT: Как правильно искать информацию
- Термин OSINT и его описание
- Цель разведки
- Немного Google Dorks
- Сайты для поиска информации
- Стеганография: Что скрывают от глаз пользователей?
- Термин Стеганография и его описание
- Работа с HEX редактором
- Учимся скрывать и находить информацию в картинке
- Работа с аудиофайлами
- Реверс-инженерия: Как работать с файлами
- Wireshark и перехват пакетов
- Пятиуровневый стек
- Работа с фильтрами и их операторами
- Коротко о видах анализа и программах
По плану я описал всю работу, которую нам предстоит провести, поэтому можем приступать к реализации.
Что такое CTF?
Начнем с того, что означает такое слово. Гугл трактует его так:
CTF (Capture The Flag, Захват флага) - соревнования по спортивному хакингу или командная игра, главной целью которой является захват «флага» у соперника. Участники делятся на команды и соревнуются в выполнении разнообразных задач. Их цели зависят от формата соревнования.
Слово "команда" пока что нас не касается, так как наша основная цель освоить базовые знания для решения CTF задач. В дальнейшем я заменю слово задача на таску (от английского слова task).
Итак, представим ситуацию. Тебе дали компьютер, точнее информацию о нем (IP адрес или логин/пароль к учетке) и сказали взломать. В реальных условиях такого рода таски встречаются достаточно часто. И чтобы со всем этим справиться я расписал алгоритм решения, который состоит из трех пунктов. По нему вам будет проще ориентировать и не будет ступора дальше.
- Гуглится все. Представим у нас есть код на Python и при его запуске выходит ошибка. Ранее такой не было и что делать в таком случае? Самое логичное решение это загуглить. Та же система работает и в решении CTF. Рекомендуется использовать англоязычные сайты, чтобы найти больше решений и ответов.
- Подбор слов. Никто не сомневается в том, что интернет дает огромное количество решений на поставленные задачи. Но бывают исключения из правил, когда пользователь неправильно создает запрос. Допустим мы получили такую ошибку из нашей программы: UnicodeDecodeError: 'utf-8' codec can't decode byte 0x84 in position 0: invalid start byte. Прежде всего не нужно копировать и вставлять все, что указано. Требуется выделить главную информацию, а именно первое слово, которое говорит о том, какого характера идет ошибка. Таким образом, шансы на решения проблемы при правильном составлении запроса увеличиваются в несколько раз.
- Метод кубиков. Проще всего объяснить такое правило будет на достаточно простом примере. Каждый персональный компьютер обрабатывает огромный поток информации за несколько секунд. На языке ассемблер создаются запросы к оперативной памяти: чтение, запись и удаление. Таким образом, из таких простых действий мы видим картинку на экране нашего монитора. По аналогии с таким примером следует выполнять последовательное решение задач. Сначала сбор информации, потом ее анализ и реализация.
Итак, мы разобрались с тем, как правильно нужно работать с CTF, теперь стоит перейти к их видам, а точнее таскам, которые встретятся на вашем пути. Далее я опишу несколько главных аспектов для работы и продемонстрирую их возможности. Потренироваться в решении вы сможете на отдельных площадках.
OSINT: Как правильно искать информацию
Итак, прежде всего следует определится с тем, что такое OSINT. Так как основная аудитория этой статьи это начинающие игроки, то я постараюсь объяснять каждый новый и непонятный термин, начиная с этого.
OSINT (Open-Source Intelligence, разведка на основе открытых данных) — сбор информации о человеке или организации из открытых источников и ее последующий анализ.
Основной целью такой разведки становятся персональные данные. Любая информация, которая связана с человеком. Геолокация мест, фамилия, имя или отчество, а также дата рождения или имя домашнего питомца. Я думаю вы поняли о чем я говорю. Но чтобы найти все это порой мало одного лишь запроса в гугле. Так как алгоритмы поиска основаны на релевантности, то есть дают максимально близкие вам запросы. Поэтому мы не всегда получаем нужную нам информацию. Чтобы это исправить следует ограничить круг поиска при помощи операторов, специальных конструкций запросов. Ниже я создал небольшую таблицу с такими конструкциями.
|
Оператор |
Описание |
Пример |
|
site |
ищет информацию на определенном сайте |
site:codeby.net CTF Zone |
|
link |
Страницы содержащие ссылку на сайт |
link:codeby.net |
|
cache |
Позволяет увидеть актуальный кэш страницы |
cache:codeby.net |
|
related |
Ищет сайты с похожим контентом |
related:codeby.net |
|
source |
Выдает информацию из новостной ленты Google News |
source:codeby.net |
|
map |
Ищет нужную информацию на картах |
map:codeby.net |
Также предлагаю рассмотреть поиск информации по одному названию. Для этого стоит обратится к сайту Namechk, он покажет занятые домены. Таким образом это поможет найти нужный сайт или его клоны. Если дело касается никнеймов людей, то здесь будет все гораздо проще. Большинство пользователей используют один и тот же никнейм в различных социальных сетях. Воспользуемся этим и при помощи образов ссылок найдем нужный нам аккаунт.
На примере социальной сети Telegram, мы можем найти канал Codeby, для этого воспользуемся шаблоном ссылок t.me. Финальный результат будет выглядеть следующим образом: https://t.me/codeby_sec. Но хочу заметить, что сработает такой поиск только в том случае если канал является открытым. Для пользователей это равноценно тому, что используется номер телефона для поиска или человек после регистрации еще не придумал юзернейм, который мы обычно видим в профиле после спецсимвола @.
Более подробную информацию о личности можно найти при помощи слитых баз данных. Такой способ эффективен, но очень затратный по времени так как найти нужную БД не так просто. Чаще всего приходится искать на форумах, сайтах и других интернет ресурсах. Из доступных и бесплатных вариантов можно привести в пример Wayback Machine, для любителей испытать удачу.
В случае если наша жертва параноик или просто информации очень и очень мало можно прибегнуть к анализу фотографий и видеофайлов. Чаще всего в них скрывается огромное количество метаданных, они то и помогут вам найти зацепку. Найти их вы можете во вкладке свойств, которая содержится в абсолютно любом файле.
Если же дело касается сайта, что чаще всего встречается в CTF, то здесь мы можем воспользоваться таким понятием как WHOIS. Это сетевой протокол, который стоит рядом с TCP и используется для установки владельца домена и подробной информации о нем. Также в решении таск может помочь сервис Censys. С регистрацией может быть доступна демо-версия, но для старта этого достаточно. Для работы с DNS серверами прекрасно подходит DNS Dumpster с его функционалом и графическим представлением всей информации. Чтобы не терять важные ссылки следует обратится к онлайн фреймворку OSINT Framework. Там вы найдете множество полезной информации и никогда не останетесь у разбитого корыта.
Стеганография: Что скрывают от глаз пользователей?
У большинства людей при виде этого слова возникает ассоциация с картинкой в которой вшита какая-либо информация. Это самый примитивный пример реализации стеганографии. В Windows создать такое можно при помощи подручных средств. Некоторые таким образом скрывают свои тайны в обычных JPEG фотографиях. Только мы с тобой будет выжимать из таких изображений все содержимое. Перед этим ознакомимся с термином стеганография.
Цифровая стеганография - это направленное сокрытие каких-либо данных в цифровых объектах (картинках, видеофайлах или звуковых дорожках).
Теперь попробуем взять какое-либо изображения из интернета и просто поменяем ему формат. Допустим у меня есть исходный файл с названием cat.jpg. При открытии операционная система использует встроенные редакторы изображений. Если я поменяю формат файла с JPG на MP3 или тот же WAV откроется уже плеер и система сообщит о том, что файл поврежден и его невозможно прочитать. Хотя на самом деле если по прежнему открыть файл с таким форматом через редактор изображений никаких проблем не возникнет. Как это происходит?
Каждый файл состоит из определенной последовательности байт. Обычно такая последовательность представлена в шестнадцатеричной системе счисления. Простым языком все картинки имеют определенную структуру, по которой система их распознает. Чтобы найти эту структуру воспользуемся HEX редактором. Каким именно вы можете выбрать сами. Также скачаем любую картинку из гугла в формате JPG. Я для работы использую такую фотографию:

Откроем ее при помощи редактора и посмотрим на последовательность байтов. Все должно выглядеть примерно так:
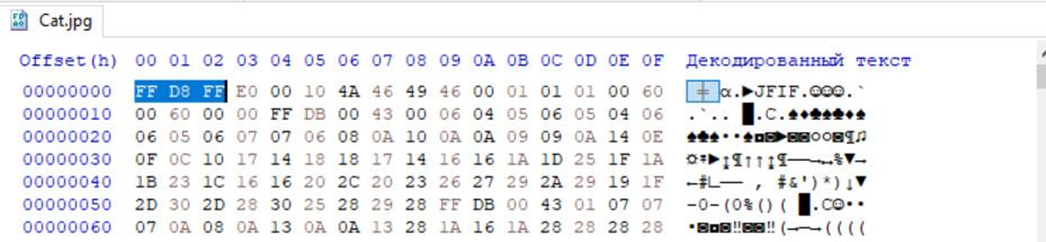
Я выделил первые три байта в памяти поскольку для JPG формата они никогда не меняются. Справа у нас кот в шестнадцатеричной системе, а слева тот же кот но в кодировке ASCII. Именно поэтому вы видите набор смайликов и непонятных символов. Неизменную последовательность байтов (в нашем случаи это FF D8 FF) принято называть сигнатурой. С ней мы подробнее познакомимся в разделе реверса, а сейчас я могу сказать, что сигнатура это подобие вашей подписи, которую вы оставляете в документе и других деловых бумажках. Кроме одинакового конца файлы имеют и отдельный конец после которого программа не будет ничего читать. В рамках нашей работы я не стану объяснять как ручным способом найти склейку файлов, потому что сейчас существует огромное количество утилит заточенных под это. Предлагаю протестировать все в реальных условиях. Берем нашу картинку и перемещаем на рабочий стол. Склейку я проведу на Windows 10, а искать скрытые данные буду при помощи Linux. После перемещения создаем архив в формате RAR и помещаем туда то, что мы хотим спрятать от посторонних глаз. После этого тут же создаем файл в формате BAT и записываем в него следующие строки: copy /b название_картинки.jpg + название_архива.zip crack_me.jpg
Сохраняем результат и запускаем. В результате таких манипуляций мы получим файл с названием crack_me.jpg. Чтобы убедиться, что он имеет скрытую информацию делаем щелчек правой кнопкой мыши по файлу и выбираем пункт открыть с помощью WinRAR. Таким образом перед нами появится темная сторона нашего файла. Чтобы эти данные обнаружить и изъять мы воспользуемся утилитой binwalk. Плавно перетекаем из Windows в Linux и пробуем наши силы. Чтобы извлечь всю информацию в терминале требуется напечатать такую команду: binwalk -e crack_me.jpg. После этого вы увидите примерно такую картину:
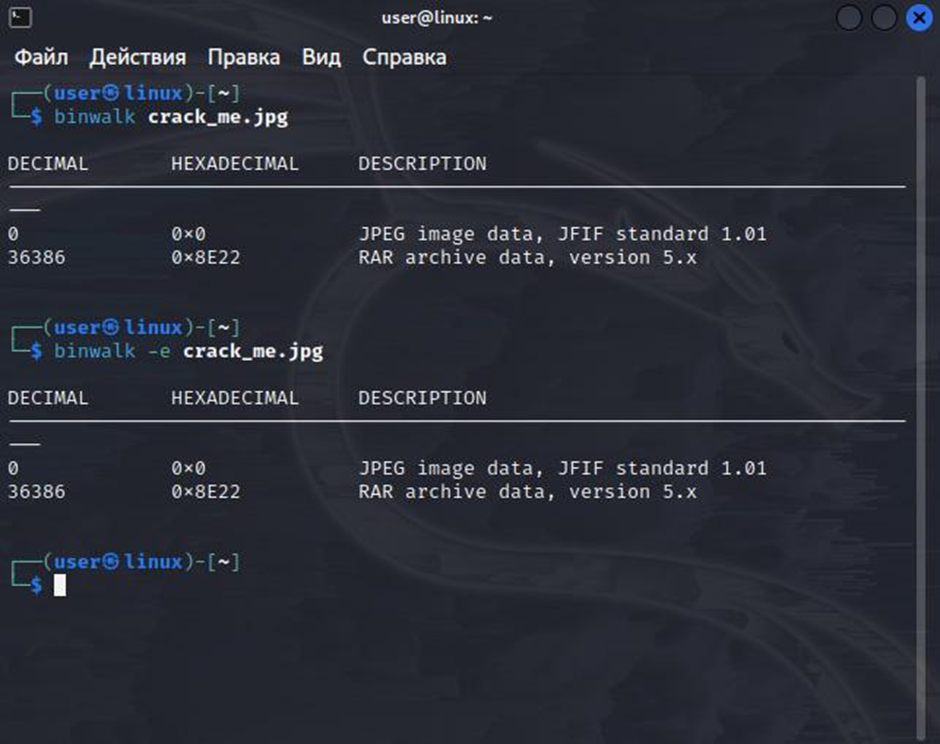
Все прошло успешно и рядом с файлом была создана папка, в нее поместили все вшитые файлы и теперь их можно с легкостью посмотреть и изучить.
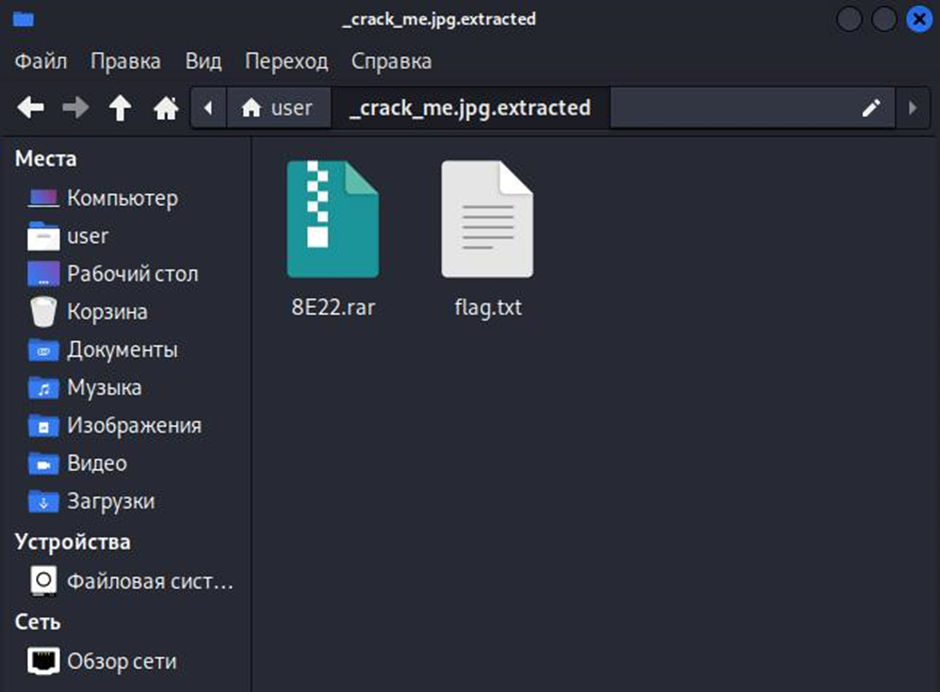
Также порой в изображениях можно найти геолокации. Обычно они прячутся в метаданных и достать их оттуда не составляет труда. Утилита exiv2 помогает просматривать всю информацию о изображениях, чтобы увидеть их требуется запустить программу с флагом -pa, а для комментариев используется -pc. Также вы можете столкнуться с таким понятием как сжатие. При помощи него тоже можно скрывать нужную информацию, в этом случае вас спасет программа stegsolve.
Что касается аудиофайлов. Здесь все значительно проще. Вам не придется делать, что-либо вручную поскольку самые простые таски вы сможете решать при помощи редактора аудио Audacity. Для примера я взял еще одно фото и попытался скрыть его в аудио дорожке. Само изображение вы видите ниже.

Итак, в результате преобразования JPG картинки в формат WAV получился довольно непонятный звук. Я загрузил его в наш редактор. Далее вам требуется сделать по тише аудиофайл и включит режим спектрограммы. Таким образом получится результат. Если же изображения не появилось следует поэкспериментировать с частотой файла. Увеличивая или уменьшая ее вы добьетесь нужного результата. Еще порой встречаются таски на логику, где дается одна аудиодорожка и никакого изображения или текста в ней нету. Здесь стоит включать логику и вероятнее всего решение скрыто в громкости файла. Самый высокий тон можно принять за единицу, а самый низкий соответственно за ноль. Таким образом можно составить закодированный в двоичную систему текст и в дальнейшем при декодировании получить флаг.
Сигнатуры для всех известных и часто используемых файлов я предоставил ниже.
|
Расширение |
Шестнадцатеричный вид |
ASCII формат |
|
JPG |
ff d8 ff e0 00 10 4a 46 49 46 00 01 |
......JFIF.. |
|
PNG |
89 50 4e 47 0d 0a 1a 0a 00 00 00 0d |
.PNG........ |
|
ZIP |
450 4b 03 04 14 00 00 00 08 00 06 93 |
PK.......... |
|
MP3 |
49 44 33 03 00 00 00 0f 6d 4b 54 41 |
ID3.....mKTA |
|
|
25 50 44 46 2d 31 2e 35 0a 25 d0 d4 |
%PDF-1.5.%.. |
|
EXE |
4d 5a 90 00 03 00 00 00 04 00 00 00 |
MZ.......... |
|
GIF |
47 49 46 38 39 61 96 00 53 00 87 00 |
GIF89a..S... |
Итак, теперь пробежимся по итогам. В этом разделе для новичков больше преобладает умение использовать софт, чем знания. По сути основная цель это просканировать файл, доказать, что в нем, что-то есть и вытащить всю информацию при помощи подручных средств. Вручную вас никто не просит этого делать. Вы можете открыть файл в формате HEX, если в обычном режиме чтения система сообщает о повреждениях. С помощью 16-тиричной системе можно установить первоначальное расширение файла и поменять его обратно. Такого типа таски могут встречаться на вашем пути, их основная цель запутать игрока и вызвать панику при помощи крайне простой ошибки.
Реверс-инженерия: Как работать с файлами
Итак, здесь прошу быть очень внимательным, поскольку информацию о реверс-инженерии каждый трактует по своему. Прежде чем погружаться в паутину двоичных систем я предлагаю ознакомится с тем, как работает передача информации. Ведь любое подключение к компьютеру происходит прежде всего благодаря протоколам.
Протокол - это набор правил, которые созданы для регулирования обмена данных между системами.
Для наглядности давай возьмем самый примитивный пример. Мы ежедневно общаемся с огромным количеством людей и перед тем как начать какой-либо диалог мы должны поприветствовать собеседника. А в конце нашего разговора не забыть попрощаться. Аналогично работает все в системе. Браузер, когда желает узнать IP-адрес сервера использует протокол системных доменных имен, он же DNS. После сервер отвечает нашей системе и передает ей нужные данные.
Также стоит помнить, что при общении мы придерживаемся определенных правил. К примеру, после приветствия у нас следует имя собеседника. Та же система применяется к интернет-протоколам. Только вместо имени используется конкретизация информации в заголовке пакета. Под этим словом понимается номер порта источника и приемника. Само же понятие порт пришло к нам для облегчения работы системы. Через них мы можем передавать больше информации чем обычно. К примеру по 21 порту мы можем скачать файл, а по 443 подключится к серверу и посмотреть что-либо. Еще стоит напомнить о таком термине как пакет. Если говорить коротко, то это файл с информацией который передается на другое устройство. Своеобразное подобие посылки, но достаточно необычной. В реальной жизни мы отправляет посылку целиком, а в интернете мы разбиваем ее на пакеты и отправляем по частям.
Также в работе интернета есть одно важное понятие уровней. Вся информация передается на определенных этапах. Чтобы не загружать мозг я коротко представил все в виде таблицы. По другому это все называется пятиуровневым стеком интернет-протоколов.
|
Что передается |
Тип уровня |
Между кем передается |
|
Данные |
Прикладной уровень |
Между браузером и сервером |
|
TCP/UDP заголовки |
Транспортный уровень |
Между операционными системами |
|
IP/TCP/UDP заголовки |
Сетевой уровень |
Между маршрутизаторами |
|
MAC/IP/TCP/UDP заголовки |
Канальный уровень |
Между сетевыми картами |
|
Двоичный код |
Физический уровень |
Между кабелями |
Для дальнейшей работы нам потребуется Wireshark. Я на примере своих вирусов покажу как перехватывать нужную информацию из пакета и правильно ее обрабатывать. Если вы являетесь внимательным читателем моих статей, то могли заметить, что такую работу я проводил в одной из своих статей.
В работе с перехватом трафика требуется владеть навыками поиска и обработки информации. Вы должны знать как правильно составлять запрос для фильтрации данных. а также знать, что нужно искать.
Чтобы продемонстрировать весь процесс работы я использовал стиллер Predator. Подробнее о его исследовании вы можете ознакомиться здесь. Приступим к разбору.
Первым делом запускаем нашу акулу. Перед вами высветится окно такого формата.
Здесь потребуется выбрать наиболее активный трафик. Если у вас нету под рукой виртуальной машины, то список будет немного короче. После выбора сразу же начинается перехват трафика. В этот момент следует запустить вирус предварительно отключив антивирус и убедившись в том, что он не унесет ваши данные за горизонт локальной сети. Так как я настроил передачу данных при помощи почты, то следовательно всю информацию вирус будет отправлять по протоколу SMTP. Но перед этим предлагаю взглянуть на результаты перехвата.
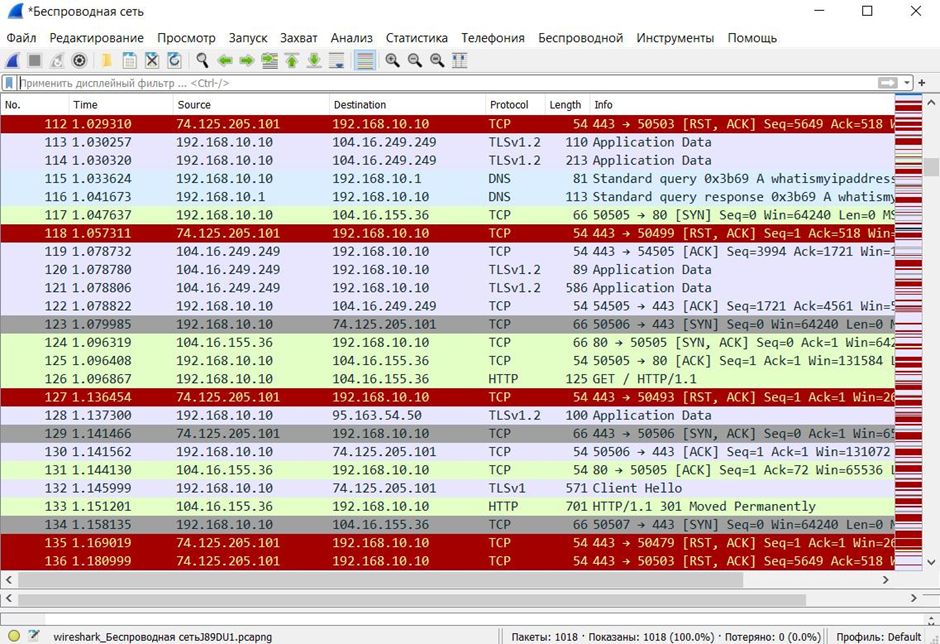
Первым делом взгляд падает на ярко-красные строки. Их рассматривать смысла никакого нет поскольку это неудачное подключение к серверу. Первым делом всегда стоит обращать внимания на зеленую подсветку, которая свидетельствует об успешной передачи пакетов. Чтобы отсеять все необходимое по ним кликаем правой кнопкой мыши по пакету, далее выбираем пункт следовать и протокол TCP. Таким образом мы попадаем на окно с информацией, которую наше устройство передавало.
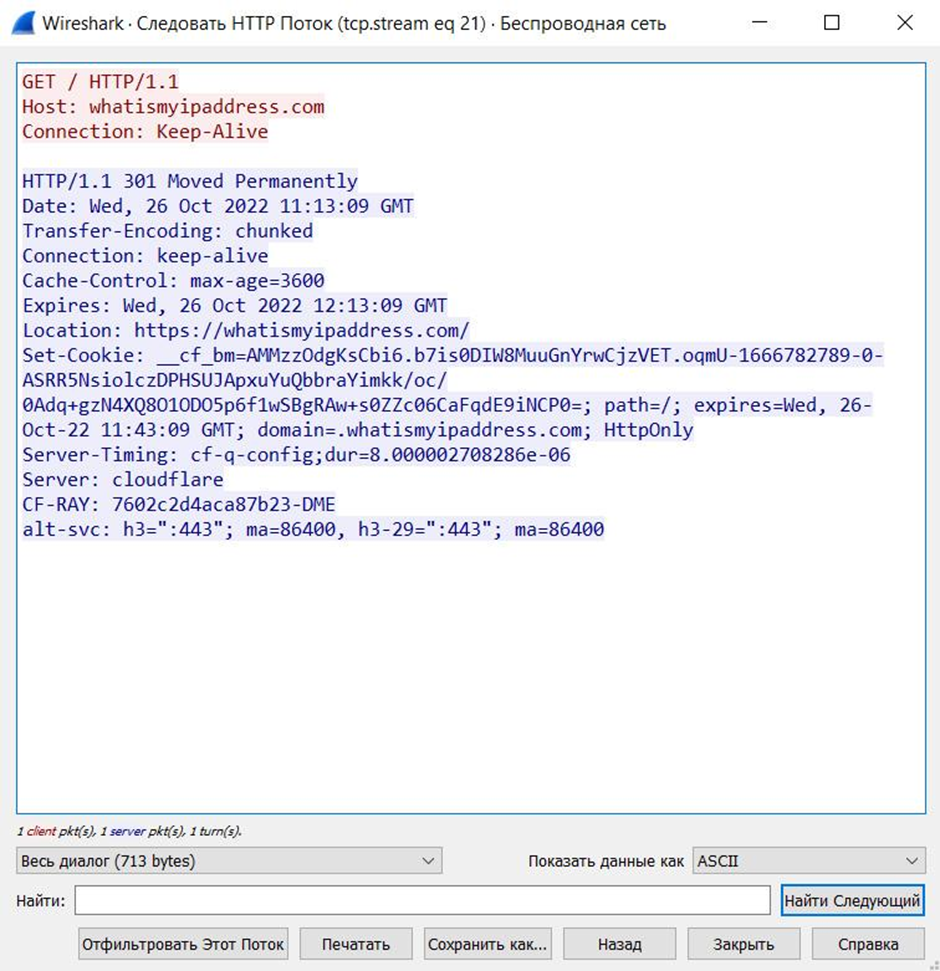
В самом пакете стоит обратить внимания прежде всего на локацию, в нашем случаи это сайт, который устанавливает внешний IP машины. В CTF обычно он будет вести на другой сайт с зацепкой. Теперь попробуем применить собственные фильтры и отсеять все пакеты с флагом SYN. В них нет ничего интересного поскольку их основная цель это подготовка и завершение подключения с сервером. Для этого в верхней строке вводим такой текст: tcp.flags.syn==1
Вы могли уже заметить, что большая часть пакетов, если не вся полностью окрашена в серый цвет, что предупреждает нас о том, что пакет является пустышкой. Но если мы хотим найти что-то ценное придется поменять тактику. Из анализа GET запроса мы узнали IP адреса получателя и отправителя. Теперь попробуем отследить полное общение устройств при помощи фильтров. В примере указан мой локальный адрес, поэтому в вашем случае он будет отличатся. Для слежки создадим такого типа запрос:
ip.dst == 192.168.10.10 && ip.src == 104.16.155.36
И теперь перед нами есть полная картина общения, по которой можно найти всю нужную информацию. Кроме этого наш вирус передавал информацию на почту и я предлагаю найти ее. Чтобы не запутаться создадим также фильтр состоящий из одного слова: smtp
Теперь перед нашими глазами информация о подключении к серверу и размере передаваемого сообщения. Для просмотра такого добра переходим во вкладку следования и изучаем пакет. Если в условии таски вам дадут порт для подключения то потребуется применить такой фильтр: tcp.port == номер_порта.
Для более понятной ориентации ниже я составил таблицу со всеми операторами и их описанием.
|
Оператор |
Описание |
|
== |
Присвоение, оно же равно |
|
!= |
Отрицание, не равно |
|
< |
Меньше |
|
> |
Больше |
|
>= |
Больше или равно |
|
<= |
Меньше или равно |
|
&& |
Логическая операция И, выполняются когда истины два условия |
|
|| |
Логическая операция ИЛИ, выполняется когда истинно одно из условий |
|
!() |
Логическая операция НЕ, выполняется когда нет совпадений со значениями в скобках |
Также я предоставил ниже аналогичную таблицу, но связанную с такими операторами как dst/src и тд.
|
Оператор |
Описание |
|
ip.addr |
Выдает пакеты где заданный IP используется как источник или приемник |
|
ip.src |
Выдает пакеты где заданный IP используется как источник |
|
ip.dst |
Выдает пакеты где заданный IP используется как приемник |
|
tcp.port |
Выдает пакеты, источником или портом назначения которого является определенный порт |
|
tcp.flags |
Выдает пакеты, в которых присутствует определенный флаг |
|
tcp.stream eq |
Следует по потоку с определенным номером |
|
tcp.seq |
Фильтрует по номеру потока |
Итак, на этом этапе работу с перехваченным трафиком можно закончить. Теперь перейдем к основным моментом анализа бинарных файлов. Если таска состоит в том, чтобы заглянуть в исходный код программы, то здесь потребуются немного другие базовые знания.
Прежде всего вы должны понимать, что реверс подразделяется на 2 большие группы анализа.
- Статический анализ (он делится на: базовый, продвинутый)
- Динамический анализ (он делится на: базовый, продвинутый)
Разберемся с тем, в чем их отличие.
- Статический анализ - он подразумевает анализ файла в обход его запуска. При помощи подручных утилит позволяет вытянуть таблицу импорта/экспорта, а также показывает строки и сигнатуры файла.
- Динамический анализ - заставляет вас открывать файл и анализировать его поведения. Как раз работа, которую мы проводили в Wireshark становится частью динамического анализа PE-файла.
На этом уровне подготовки я не стану рассказывать о упаковщиках, крипторах и деобфускаторов, чтобы случайно не взорвать ваш мозг. Поэтому ниже я предоставил список, который поможет в анализе файла и поиска зацепок для решения CTF. В следующих статьях я более подробно расскажу об устройстве файла и его составе, а пока что рекомендую использовать такой набор тулкит:
Статический анализ: Detected It Easy, FileAlyzer, Import REConstructor, Explorer Suite.
Динамический анализ: dnSpy, dotPeek, ExtremeDump, ProcessExplorer. Regshot.
Теперь можно официально заявить, что посвящение в юные CTF-игроки завершено и можно переползать за черту завершения.
Заключение
Итак, в рамках этой статьи я поверхностно ознакомил вас с основными моментами в работе с CTF, дал небольшую базу знаний, хотя в большей степени новичку требуется уметь правильно обращаться с программой, ну а в дальнейшем уже накапливать и применять знания в сфере информационной безопасности.